
ここ最近「これOCRで読み取ってデータとして保存できない?」と相談を受ける機会が多くなってきました。いろいろな方法がありますが、WordやExcelのデータ取り込み機能を利用して、文字として取り込む方法が一番手軽で簡単だと思います。ただ、Office製品を利用する場合、ライセンス等のコストが発生してしまったり、自動化を考えた際に複雑な制約が発生する可能性があります。
他に良い方法がないか探していたところ、Googleが支援している「Tesseract」と呼ばれるOCRライブラリを見つけました。日本語にも対応しているようなので少し触ってみました。
Tesseractとは
みんな大好きGemini先生に「Tesseract」について聞いてみました。
Tesseractは、オープンソースのOCR(Optical Character Recognition:光学文字認識)ライブラリです。簡単に言うと、画像の中にある文字を読み取って、編集可能なテキストデータに変換してくれるツールです。
簡潔にわかりやすく説明すると以下のようになります。
- 何をするもの?
- 写真やスキャンした書類、PDFなど、画像形式になっている文字を認識して、Wordやメモ帳で使えるようなテキストデータ(文字情報)に変換します。
- どんな特徴があるの?
- 無料(オープンソース): 誰でも自由に利用でき、商用利用も可能です。
- 高性能: Googleが開発に関わっており、非常に高い認識精度を誇ります。
- 多言語対応: 日本語はもちろん、英語、中国語、韓国語など、100以上の言語に対応しています。
- プログラミングで利用: PythonやJavaなど様々なプログラミング言語から呼び出して利用できます。そのため、自動化システムに組み込んだり、Webサービスの一部として利用したりすることが得意です。
- 何に使われるの?
- 古い書類のデジタル化
- 名刺のスキャン
- 画像内の文字検索
- Webサイトからの情報抽出(スクレイピング)
- 自動データ入力システム
一言でまとめると、Tesseractは「画像の中の文字を、誰でも無料で、しかも高精度にテキスト化できる、便利なプログラミングツール」です。
Tesseractを触ってみた
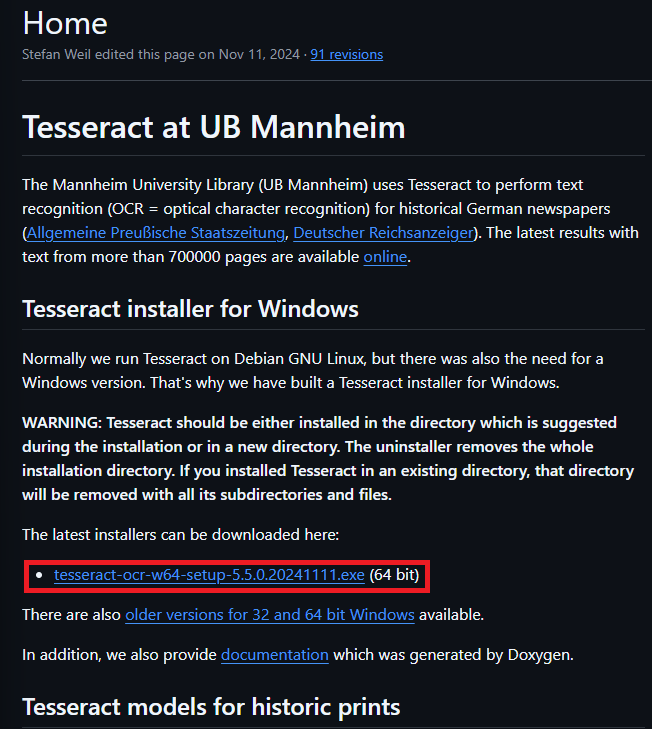
Tesseractのインストール方法
Tesseractは主にLinux系とWindows向けに開発がされているようです。公式サイトからWindows向けのインストールexeがダウンロード可能でしたので、それを利用します。
以下のサイトからWindows版のEXEをダウンロードします。(以前は32bit版も公開されていたようですが、現在は64bit版しか存在しないようです。)
ダウンロードしたEXEを実行します。基本的にはインストールウィザードに従ってデフォルトのまま「Next」でよいのですが、日本語を読み取る場合は2箇所だけ注意が必要です。
「OK」をクリックします。
「NEXT」をクリックします。
利用規約を確認し、問題がなければ「I Agree」をクリックします。
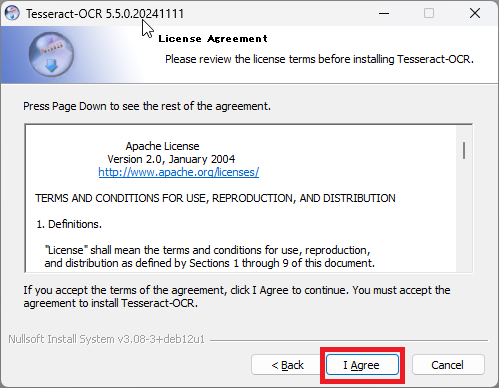
「Install for anyone using this computer」が選択されていることを確認し「Next」をクリックします。
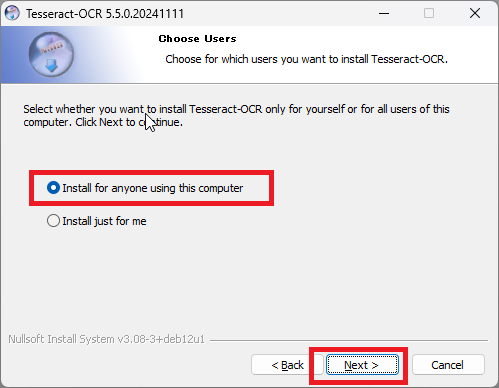
日本語を読み取る場合、ここで指定する必要があります。「□ Additional script data (download)」と「□ Additional language data (download)」をそれぞれ展開し、「Japanese」にチェックを入れます。※誤って「Javanese」を選択しないように注意しましょう。
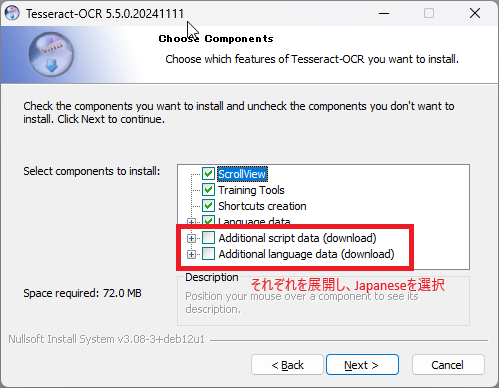
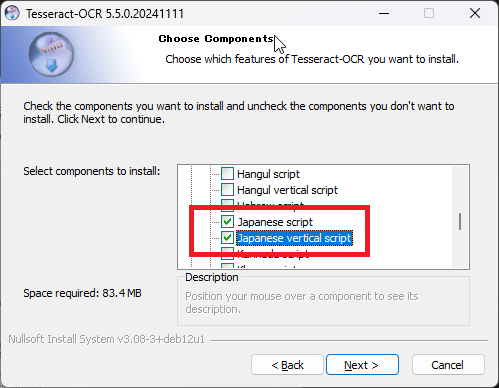
選択が完了したら「Next」を選択します。
「Next」を選択します。
「Install」を選択します。
「Next」をクリックします。
「Finish」をクリックします。
これでインストール作業は完了です。
Tesseractの使い方
今回はコマンドプロンプトから実行してみます。基本的な実行構文は以下です。
"C:\Program Files\Tesseract-OCR\tesseract.exe" [入力画像ファイル名] [出力ファイル名(拡張子なし)] -l jpn- “C:\Program Files\Tesseract-OCR\tesseract.exe”
- Tesseractをインストールしたディレクトに存在するtesseract.exeを選択してください。上記はデフォルトでインストールした場合です。もしインストール場所を変更した場合は適宜変更してください。
- [入力画像ファイル名]
- OCR処理を行いたい画像ファイルの名前を指定します。(例: image.png, scan.jpg, document.tif)
- [出力ファイル名(拡張子なし)]
- OCR処理の結果、テキストが保存されるファイルの名前を指定します。拡張子(例: .txt)は自動的に付与されるため、ここでは拡張子を含めない名前を指定します。(例:
output_text,result,document_content)
- OCR処理の結果、テキストが保存されるファイルの名前を指定します。拡張子(例: .txt)は自動的に付与されるため、ここでは拡張子を含めない名前を指定します。(例:
- -l jpn
- OCR処理に使用する言語を指定するオプションです。-l の後に言語コードを指定します。
- jpn: 日本語を指定する言語コードです。
実際に試してみます。今回はTesseractのWikipediaページの一部を画像で保存し、読み込んでみます。


上記画像をDドライブのworkフォルダに「image.jpeg」というファイル名で保存します。
以下のコマンドをコマンドプロンプトで実行しました。
"C:\Program Files\Tesseract-OCR\tesseract.exe" "D:\work\image.jpeg" output_text -l jpn
実行は正常に完了したように見えますが、出力ファイルの「output_text.txt」が見つかりません。探してみると、コマンドを実行したディレクトリ(この場合はコマンドプロンプトを開いたときのカレントディレクトリ)に作成されていました。
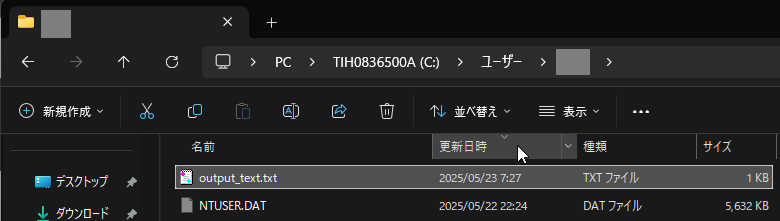
そこで、出力ファイルをフルパスで指定してみました。
"C:\Program Files\Tesseract-OCR\tesseract.exe" "D:\work\image.jpeg" "D:\work\output_text" -l jpnすると、指定したディレクトリに出力結果が作成されました。
中身を確認してみます。左側は処理対象の画像、右側は処理結果のテキストです。

文字の折り返しは概ね正しく表現されており、パッと見ただけでは正しいように思えます。ただ、よく見てみるとWikipediaで[]で表現されている箇所が正しく認識されていませんでした。とはいえ、無料で日本語をここまで正しく読み取ることができるのは素晴らしいと思います。
まとめ
この記事では、Googleが支援するオープンソースのOCRライブラリ「Tesseract」について、その概要からWindows環境への具体的なインストール方法、そしてコマンドラインを使った基本的な使い方と日本語の読み取りテストまでを解説しました。
- Tesseractの魅力: 無料で利用でき、多言語対応(日本語含む)、かつ高い認識精度を誇ります。プログラミング言語からの呼び出しも容易で、自動化にも適しています。
- 簡単な導入: Windows向けのインストーラーが提供されており、本記事の手順に沿えば日本語対応の設定も含めてスムーズに導入できます。
- 実践的な使い方: コマンドラインでの基本的な実行方法や、出力ファイルの指定方法、簡単な読み取りテストの結果を紹介しました。
- 注意点: 完璧な認識ではないものの、無料ツールとしては非常に高性能です。
手軽にOCRを試してみたい方や、業務で画像からの文字起こしが必要な方、OCR機能をシステムに組み込みたいと考えている方にとって、Tesseractは有力な選択肢の一つとなるでしょう。


コメント